
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Spring
- redis
- java
- ReactJS
- Design Patterns
- JVM
- jsp
- Oracle
- jenkins
- ubuntu
- db
- laravel
- it
- javascript
- php
- Git
- tool
- Gradle
- IntelliJ
- linux
- devops
- Spring Boot
- elasticsearch
- 맛집
- MySQL
- 요리
- AWS
- Spring Batch
- Web Server
- springboot
- Today
- Total
아무거나
Spring Batch 6편 - Chunk-Oriented Processing 본문
Chunk-Oriented Processing (Chunk 지향 처리)
이전글: Spring Batch 5편 - Spring Batch Scope & Job Parameter
작업코드: 작업코드
Chunk
Spring Batch 의 Chunk 란 각 커밋 사이에 처리되는 row 수를 의미한다. 즉, 한 번에 하나씩 데이터를 읽어 Chunk 라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다루는 것 을 Chunk 지향 처리라고 한다.
또한 Chunk 단위로 트랜잭션을 수행하기 때문에 실패한 경우엔 해당 Chunk 만큼만 롤백 이 되며, 이전에 커밋된 트랜잭션 범위까지는 반영된다.

상기 이미지의 프로세스는 아래와 같다.
- Reader 가 누적해서 읽어 Chunk Size 를 맞춤
- Processor 에선 1개씩 Chunk 전부 Process 처리
- 가공된 데이터들을 별도의 공간에 모은 뒤, Chunk 단위만큼 쌓이게 되면 Writer 에 전달하고 Writer 는 일괄 저장
즉, Reader와 Processor에서는 1건씩 다뤄지고, Writer에선 Chunk 단위로 처리
for (int i=0; i<totalSize; i+=chunkSize) { // chunkSize 단위로 묶어서 처리
List items = new Arraylist();
for (int j=0; j<chunkSize; j++) {
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);
}
ChunkOrientedTasklet
Chunk 지향 처리의 전체 로직을 다루는 것은 ChunkOrientedTasklet 클래스이다. 여기서 중요한건 execute() 이다. execute() 메서드 내부 코드를 보면
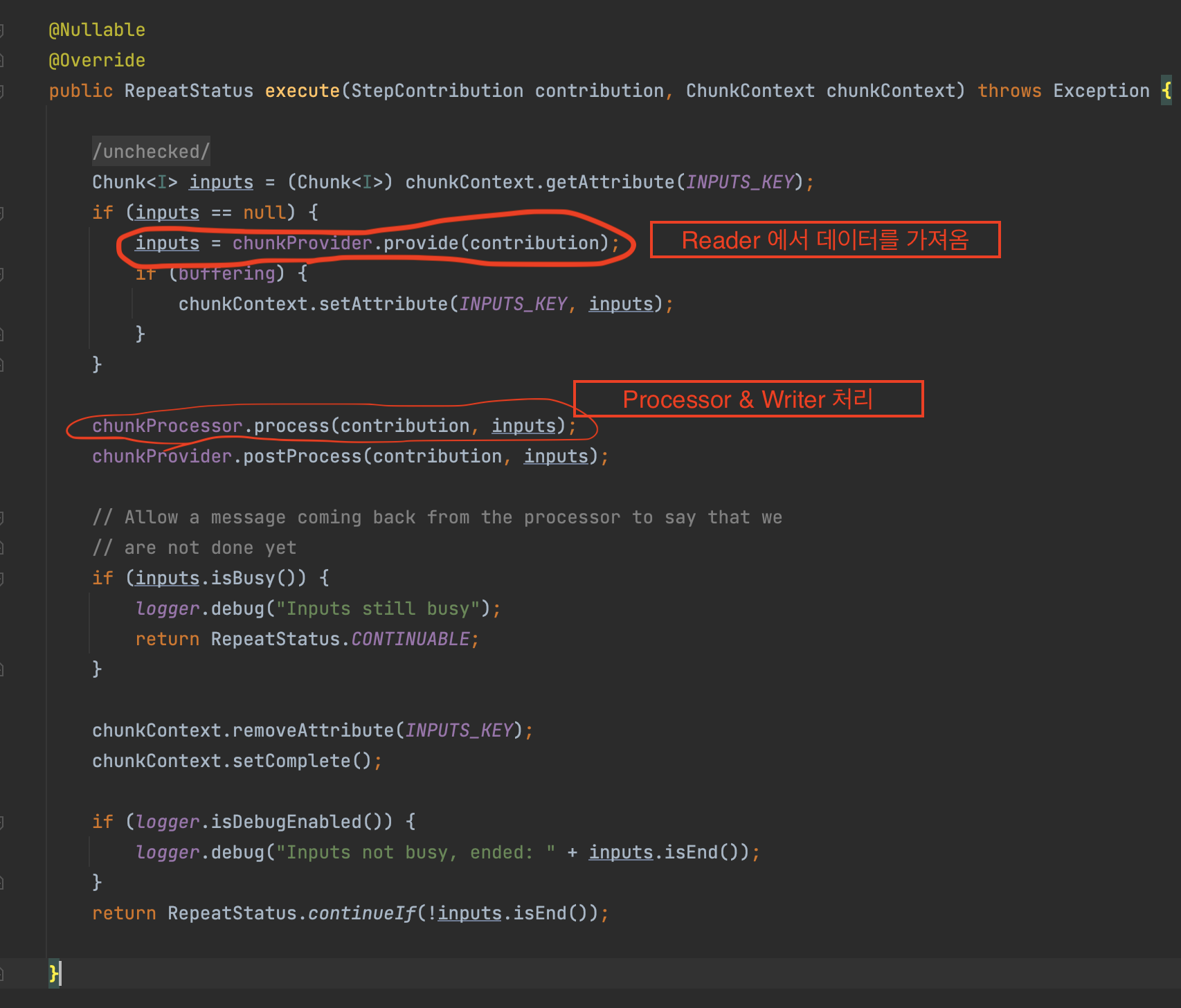
- chunkProvider.provide()로 Reader에서 Chunk size만큼 데이터를 가져옴
- chunkProcessor.process() 에서 Reader로 받은 데이터를 가공(Processor)하고 저장(Writer)
어떻게 데이터를 가져오는지 확인하려면 chunkProvider.provide() 내부 코드를 보자.
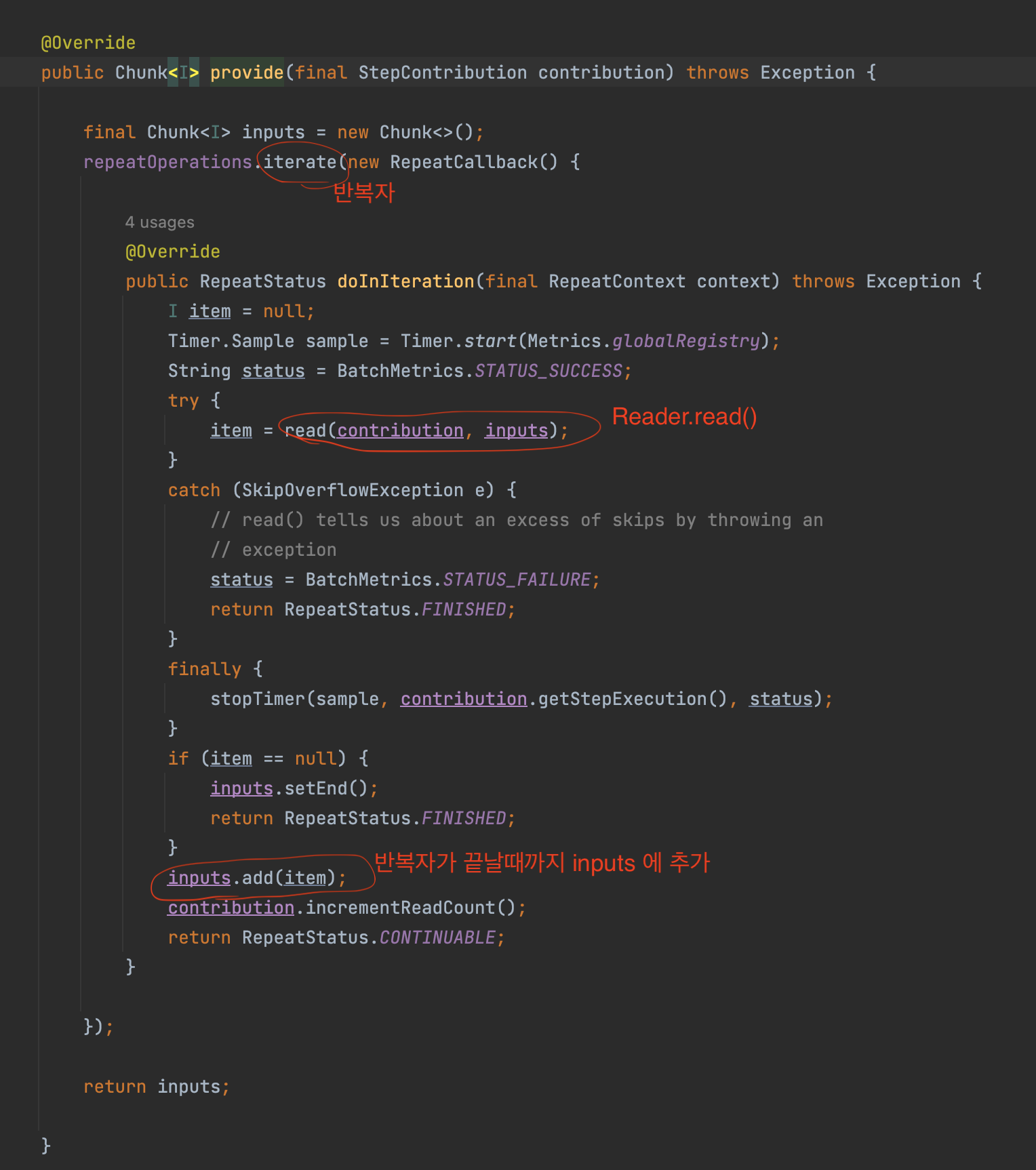
inputs이 ChunkSize 만큼 쌓일때까지 read()를 호출합니다. 이 read() 는 내부를 보시면 실제로는 ItemReader.read를 호출합니다.
@Nullable
protected I read(StepContribution contribution, Chunk<I> chunk) throws SkipOverflowException, Exception {
return doRead(); // 이거
}
/**
* Surrounds the read call with listener callbacks.
* @return the item or {@code null} if the data source is exhausted
* @throws Exception is thrown if error occurs during read.
*/
@Nullable
protected final I doRead() throws Exception {
try {
listener.beforeRead();
I item = itemReader.read(); // 이거
if(item != null) {
listener.afterRead(item);
}
return item;
}
catch (Exception e) {
if (logger.isDebugEnabled()) {
logger.debug(e.getMessage() + " : " + e.getClass().getName());
}
listener.onReadError(e);
throw e;
}
}
즉, ItemReader.read에서 1건씩 데이터를 조회해 Chunk size만큼 데이터를 쌓는 것이 provide()가 하는 일입니다.
SimpleChunkProcessor
ChunkProcessor 는 Processor와 Writer 로직을 담고 있다.
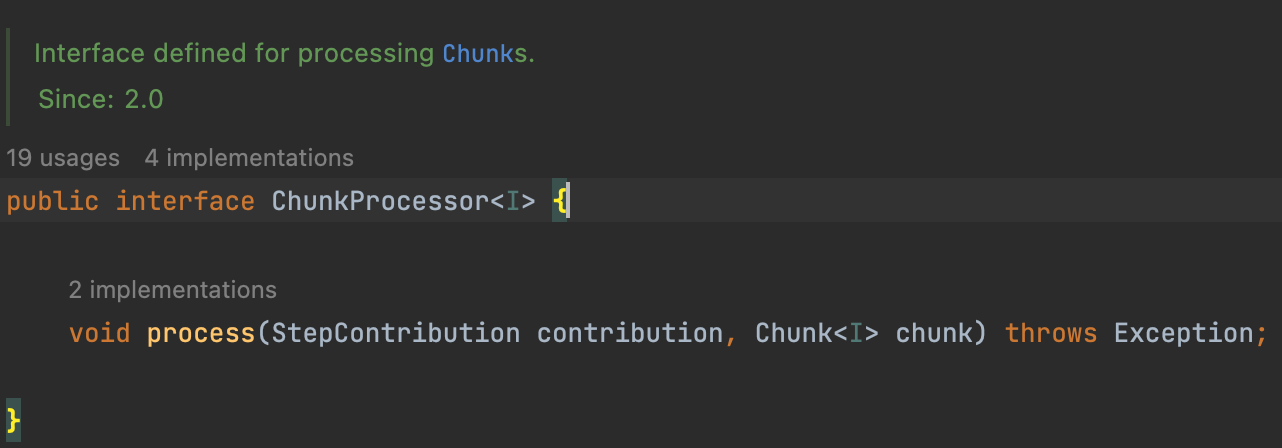
실제 구현체는 기본적으로 사용되는 것이 SimpleChunkProcessor 이다.
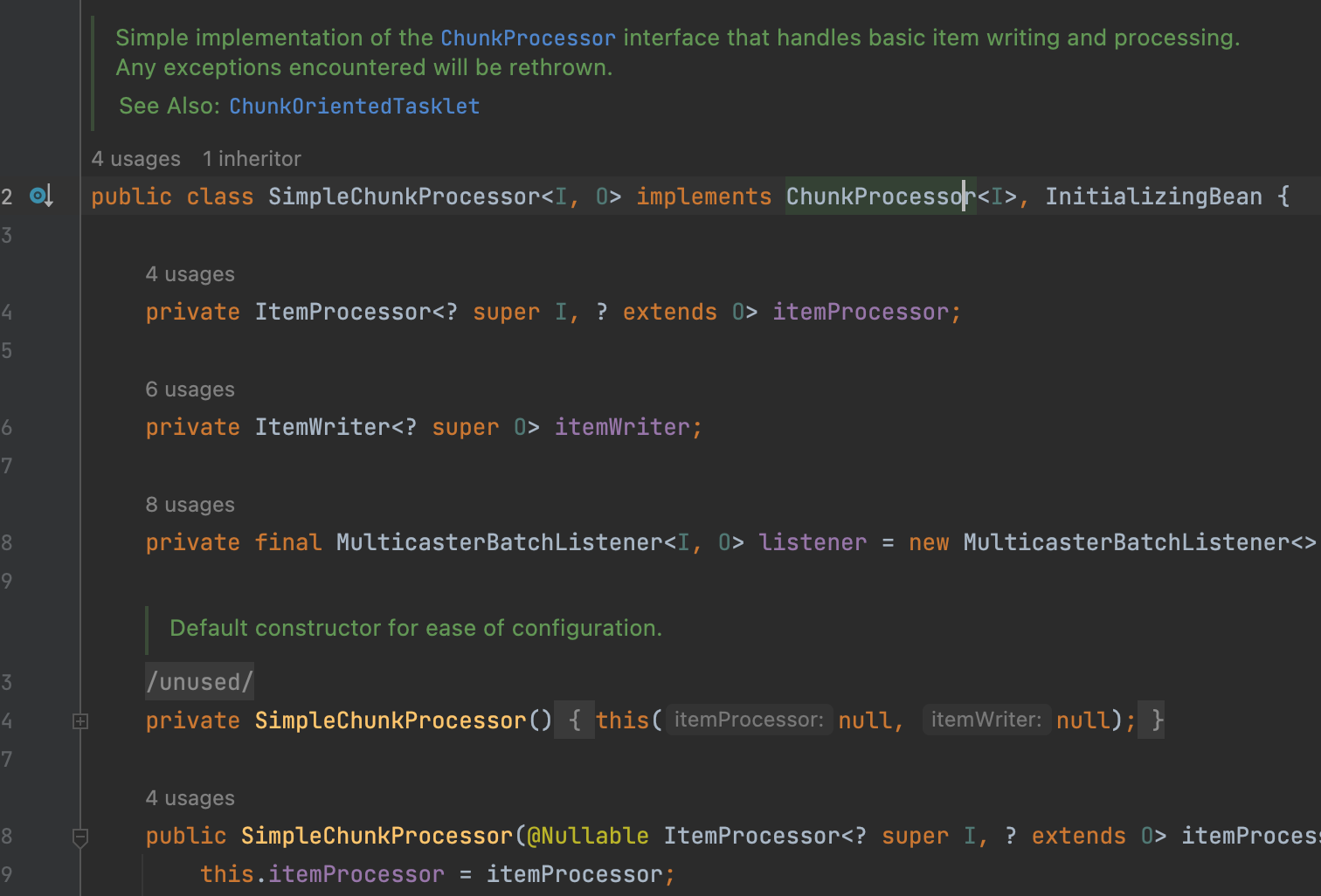
상기 클래스를 보면 Spring Batch에서 Chunk 단위 처리를 어떻게 하는지 아주 상세하게 확인할 수 있으며 처리를 담당하는 핵심 로직은 process() 이다. 해당 process() 는 하기 코드를 참고하자.
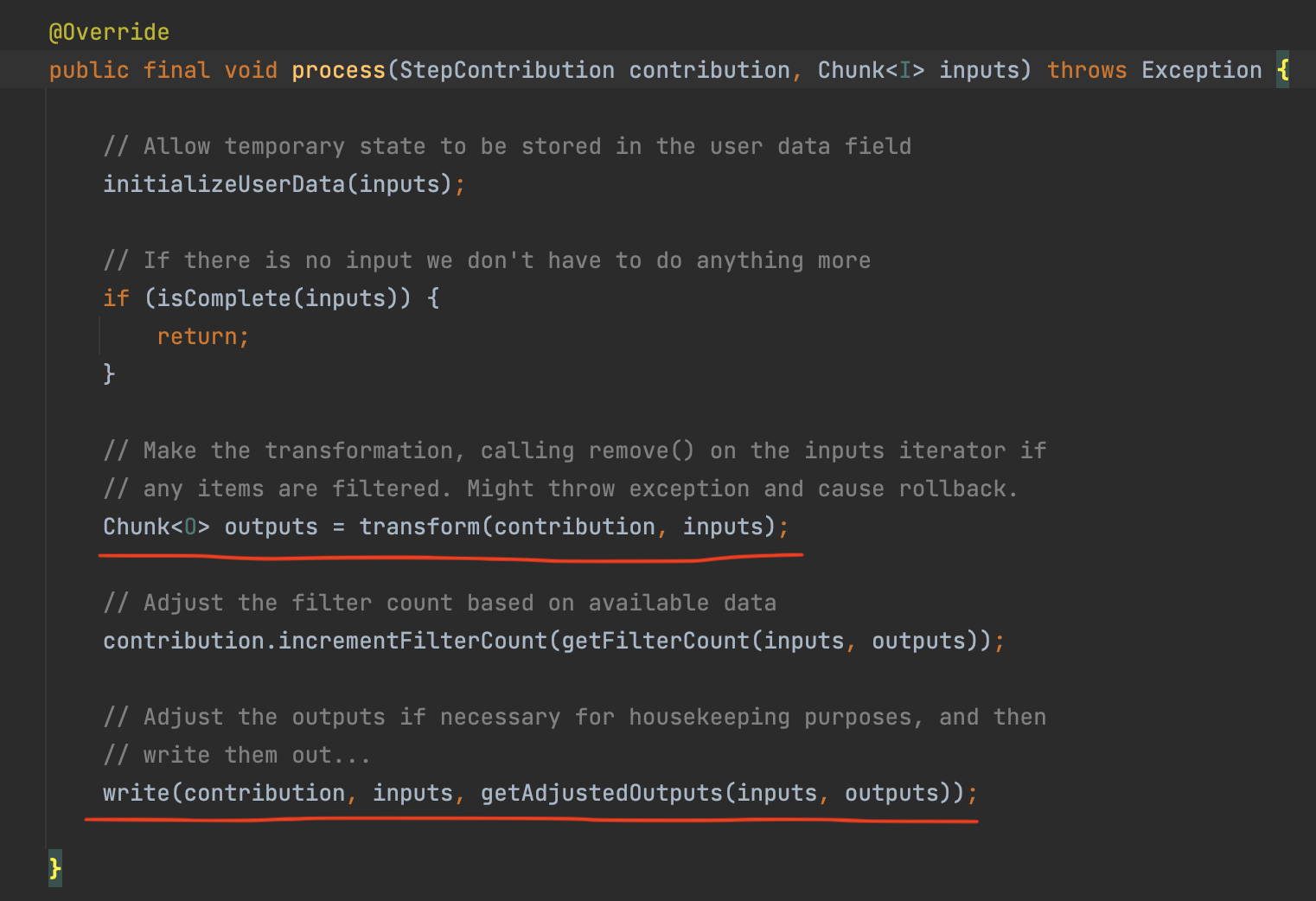
Chunk<I> inputs를 파라미터로 받습니다. 해당 데이터는 앞서 chunkProvider.provide() 에서 받은 ChunkSize 만큼 쌓인 item 이며, transform() 에서는 전달 받은 inputs을 doProcess()로 전달하고 변환값을 받는다.
transform()을 통해 가공된 대량의 데이터는 write()를 통해 일괄 저장되고 write()는 저장이 될수도 있고, 외부 API로 전송할 수 도 있습니다. 이는 개발자가 ItemWriter를 어떻게 구현했는지에 따라 달라진다.
여기서 transform()은 반복문을 통해 doProcess()를 호출하는데, 해당 메소드는 ItemProcessor의 process()를 사용한다.
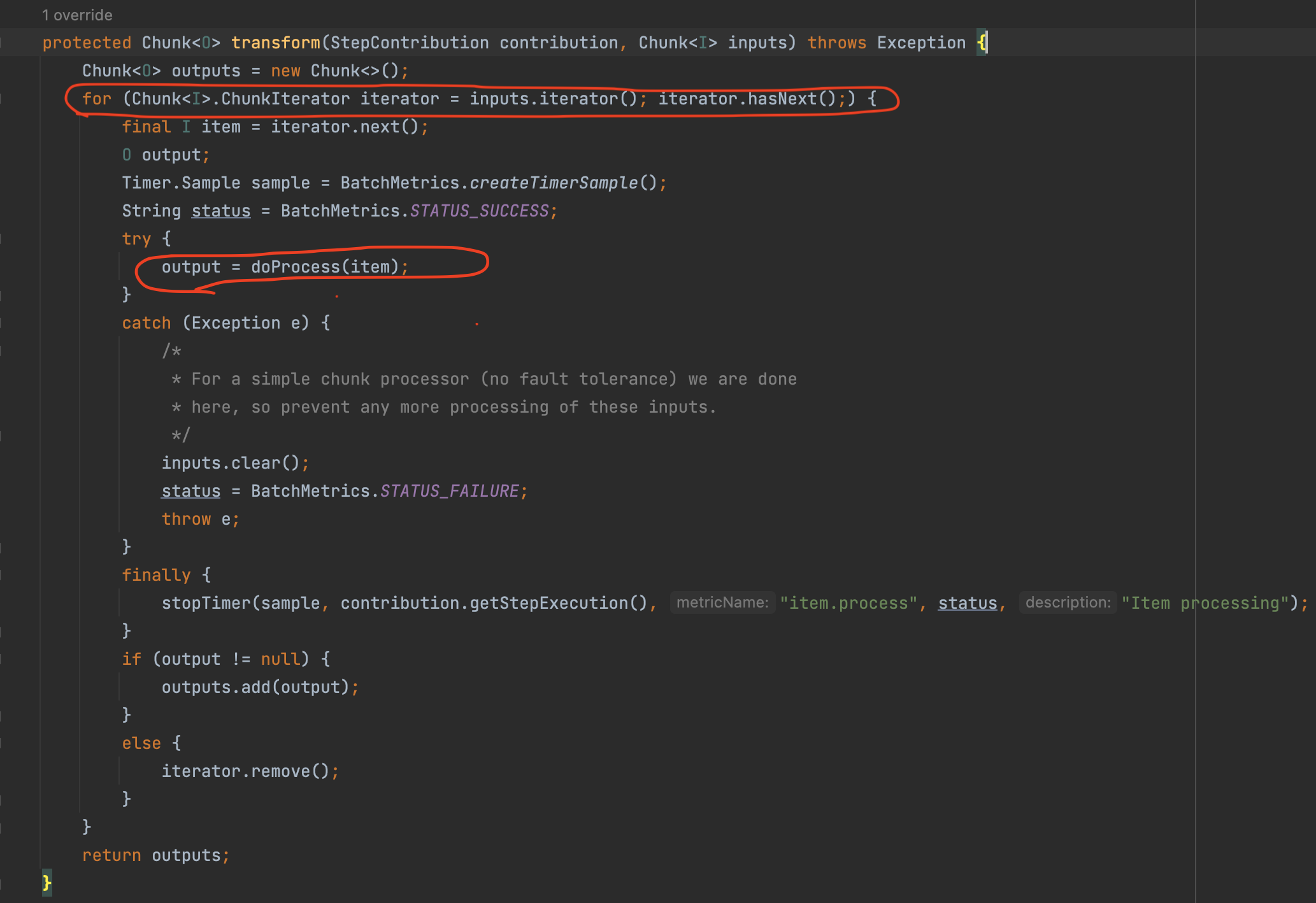
doProcess() 를 처리하는데 만약 ItemProcessor가 없다면 item을 그대로 반환하고 있다면 ItemProcessor의 process()로 가공하여 반환한다.
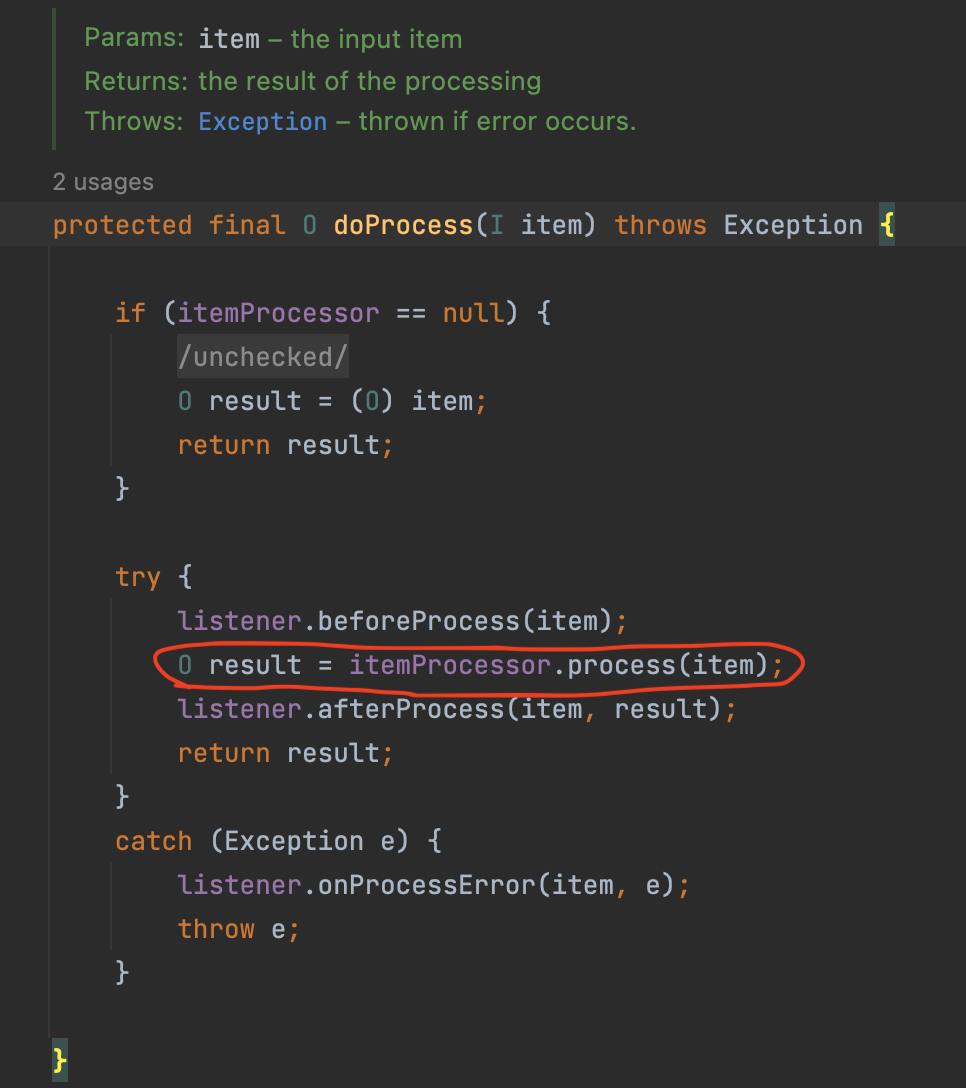
그리고 이렇게 가공된 데이터들은 위에서도 나와있듯이 SimpleChunkProcessor의 doWrite() 를 호출하여 일괄 처리 한다.
Page Size vs Chunk Size
Page Size와 Chunk Size는 서로 의미하는 바가 다르다. Chunk Size는 한번에 처리될 트랜잭션 단위이며, Page Size는 한번에 조회할 Item의 양이다.
PagingItemReader의 부모 클래스인 AbstractItemCountingItemStreamItemReader의 read() 메소드를 먼저보면 doRead() 를 호출하며 아래와 같다.
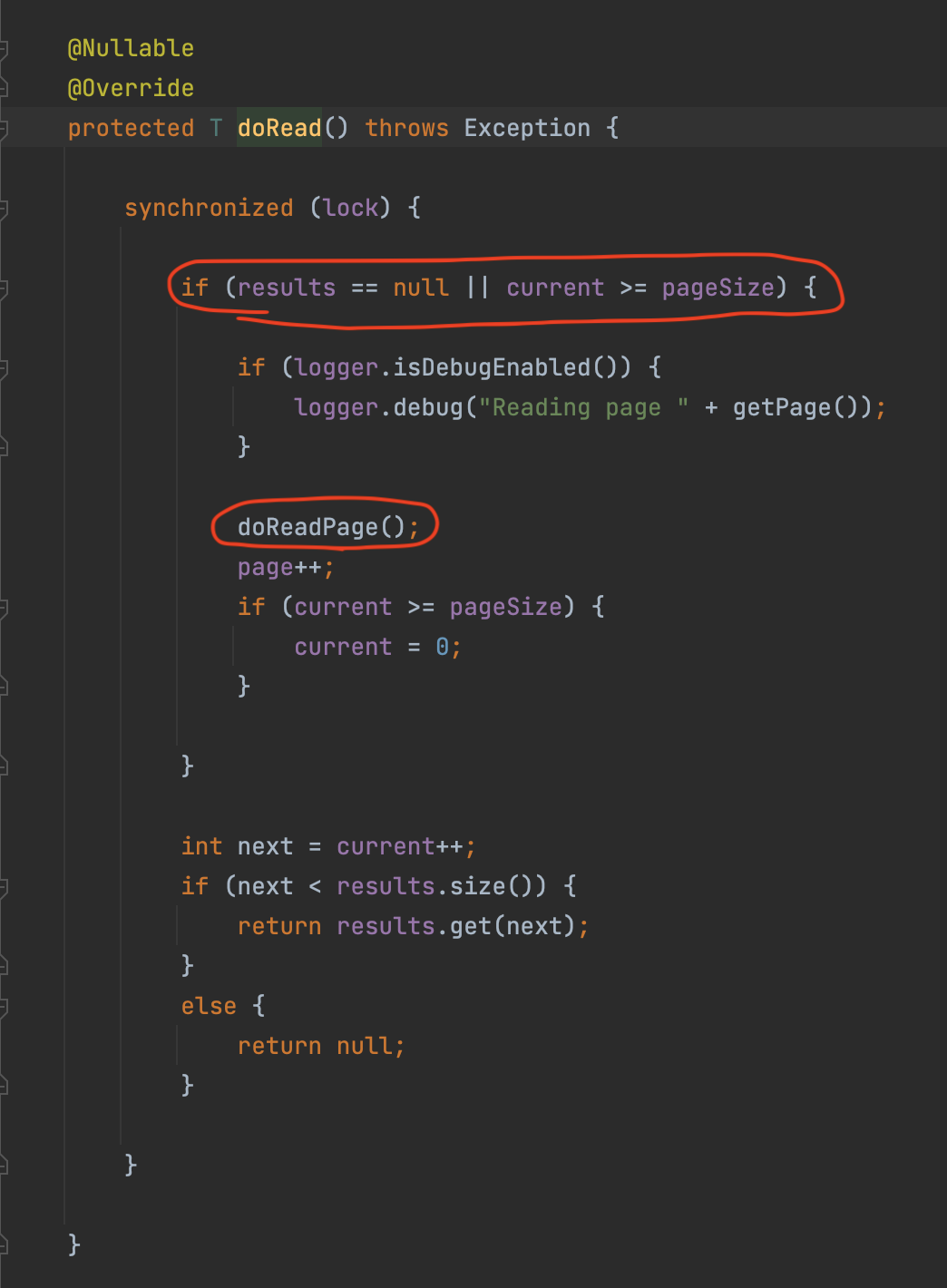
doRead() 에서는 현재 읽어올 데이터가 없거나, Page Size를 초과한 경우 doReadPage()를 호출한다. 읽어올 데이터가 없는 경우는 read 가 처음 시작할 때를 얘기한다.
Page Size를 초과하는 경우는 예를 들면 Page Size가 10인데, 이번에 읽어야할 데이터가 11번째 데이터인 경우이며 이럴 경우 Page Size를 초과했기 때문에 doReadPage() 를 호출한다고 보면 된다.즉, Page 단위로 끊어서 조회하는 것입니다. (Ex: 게시판 만들기에서 페이징 조회를 떠올려보시면 쉽게 이해가 될 것이다.)
doReadPage()부터는 하위 구현 클래스에서 각자만의 방식으로 페이징 쿼리를 생성하며 여기서는 보편적으로 많이 사용하시는 JpaPagingItemReader 의 doReadPage() 코드를 살펴보자.
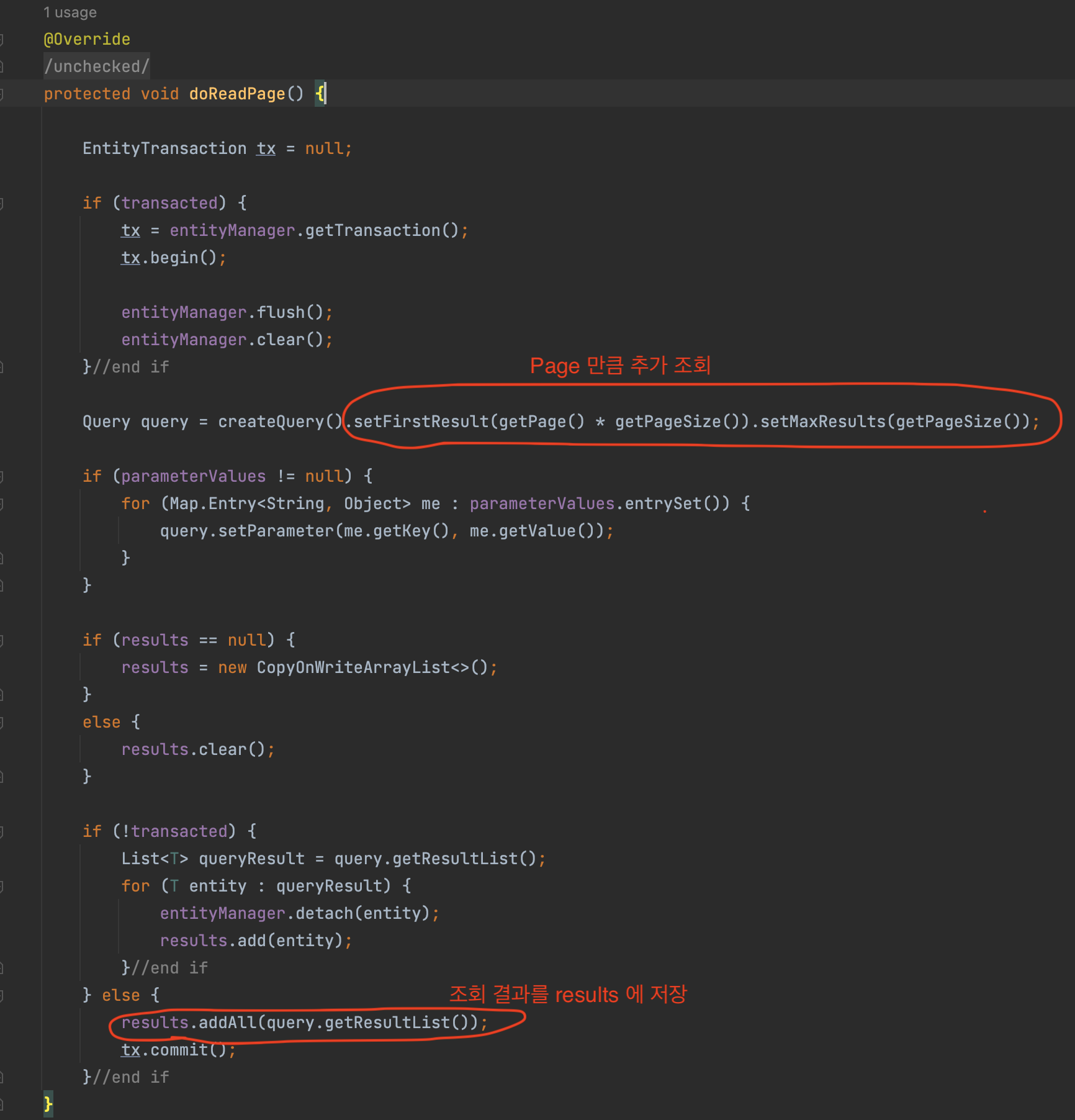
Reader 에서 지정한 Page Size 만큼 offset, limit 값을 지정하여 페이징 쿼리를 생성( createQuery() ) 하고, 사용 ( query.getResultList() ) 한다. 쿼리 실행 결과는 results 에 저장한다. 이렇게 저장된 results 에서 read() 가 호출 될 때마다 하나씩 꺼내서 전달한다.
즉, Page Size 는 페이징 쿼리에서 Page 의 Size 를 지정하기 위한 값 이다.
만약 PageSize 가 10이고, ChunkSize 가 50 이면 ItemReader 에서 Page 조회가 5번 일어나면 1번의 트랜잭션이 발생하여 Chunk 처리가 되므로 한 번의 트랜잭션 처리를 위해 5번의 쿼리 조회가 발생하므로 성능상 이슈가 발생할 수 있다.
그래서 Spring Batch 의 PagingItemReader 에는 클래스 상단에 주석이 기재되어있다.
Setting a fairly large page size and using a commit interval that matches the page size should provide better performance. (상당히 큰 페이지 크기를 설정하고 페이지 크기와 일치하는 커미트 간격을 사용하면 성능이 향상됩니다.) 또한, 성능상 이슈외에도 2개 값을 다르게 할 경우는 JPA를 사용할 경우 영속성 컨텍스트가 깨지는 문제도 발생한다고 한다.
2개 값이 의미하는 바가 다르지만 위에서 언급한 여러 이슈로 인하여 2개 값을 일치시키는 것이 보편적으로 좋은 방법이다.
참고
- https://jojoldu.tistory.com/
'Java & Kotlin > Java' 카테고리의 다른 글
| JVM Heap 모니터링 및 Heap Dump 분석 (0) | 2023.03.09 |
|---|---|
| Setter 사용을 지양하자. (0) | 2022.11.26 |
| Java Stream 이란 (0) | 2022.08.11 |
| Java 메모리(with. JVM) 관련 정리 (0) | 2022.07.27 |
| Garbage Collection (요약정리본) (0) | 2022.07.27 |

